Clusteranalyse
kommt beim Data Mining oder explorativer Datenanalyse zum Einsatz.
Clusteranalyse sucht nach Ähnlichkeiten in den Objekten und gruppiert
diese.
Dagegen werden die Merkmale der Objekte
nicht analysiert (--> Faktoranalyse)
zurück zum Glossar (Clusteranalyse)
Datenreduktionsverfahren, um Zusammenhänge überschaubarer zu machen.
Im Gegensatz zur Diskriminanzanalyse ein Strukturen-entdeckendes Verfahren.
Zur Kategorie der Explorativen Datenanalyse gehörendes Verfahren.
Im Gegensatz zur Faktorenanalyse werden Fälle, Individuen oder Objekte gruppiert, nicht die Merkmale oder Variablen.
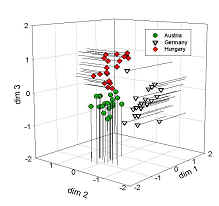
Die Merkmale der Objekte spannen einen vieldimensionalen Raum auf, in dem sich die Objekte befinden.
Gesucht wird nun nach Clustern, also nach Gruppen von Objekten, die in sich näher beieinanderliegen als andere Objekte.
Sogenannte Distanzmasse beschreiben den Abstand von Objekten oder Clustern untereinander.
Skalenniveau: Kontinuierlich.
Hierarchische Clusteranalyse.
Bei diesem Verfahren fasst man zu Beginn jedes einzelne Objekt als eigenständigen Cluster auf.
Nun sucht man die beiden Objekte (Cluster), die den geringsten Abstand zueinander haben.
Diese beiden Objekte fasst man zu einem neuen Cluster zusammen.
Nun sucht man wieder diejenigen beiden Cluster mit dem geringsten Abstand zueinander und bildet daraus wieder einen Cluster.
Bei jedem Schritt vermindert sich also die Anzahl Cluster um 1.
Diese Methode endet genau dann, wenn die zuvor spezifizierte minimale Clusteranzahl erreicht ist.
k-means Clusteranalyse
Bei diesem Verfahren sucht man im ersten Schritt eine definierte Anzahl Objekte, die möglichst weit (aber nicht zu weit) voneinander entfernt liegen.
Diese Objekte sind die anfänglichen Clusterzentren.
Dann wird jedes noch verbleibende Objekt dem jeweils nächsten Cluster zugewiesen.
Nach jeder Zuweisung eines Objektes zu einem bereits bestehenden Cluster wird das Zentrum dieses Clusters neu berechnet.
Distanzmasse
Aus rechentechnischen Gründen werden darunter immer Abstandsquadrate verstanden.
Durchschnitt
Der Abstand zweier Cluster ist der Durchschnitt der (euklidischen) Abstandsquadrate der einzelnen Objekte der beiden Cluster.
(Die Abstände eines jeden Objekts des einen Clusters mit jedem Objekt des anderen Clusters werden gemittelt)
Centroid
Der Abstand zweier Cluster ist das Quadrat der euklidischen Distanz zwischen den beiden Clustermittelpunkten.
Methode von Ward
Hier wird für jede Dimension eine ANOVA durchgeführt. Die Summe der Quadratesummen ZWISCHEN den beiden Clustern wird als Abstand aufgefasst.
Kleinster Abstand
Das (euklidische) Abstandsquadrat der beiden nächsten Objekte.
An dieser Stelle sind die Clustergrenzen also am nächsten beieinander.
Grösster Abstand
Das (euklidische) Abstandsquadrat der beiden entferntesten Objekte.
An dieser Stelle sind die Clustergrenzen also am entferntesten voneinander weg.
Anwendungsbeispiele:
Demographische Analysen (Feststellen des Wahlverhaltens in Abhängigkeit von Altersklassen)
Marktanalysen (Feststellen des Kaufverhaltens hinsichtlich bestimmter Produkte und bestimmter Bevölkerungsgruppen)
Erstellung von Kundenprofilen bezüglich des Kaufverhaltens (Feststellen, dass Kunden, die Produkt A gekauft haben, danach zu 40% auch Produkt B gekauft haben. --> Anschreiben aller A- Besitzer, um den Kauf von B anzukurbeln.)
17.06.2006
zurück zum Glossar (Clusteranalyse)