Entscheidungsbäume Klassifikationsbäume
Regressionsbäume
Verfahren,
um Zusammenhänge bei komplexem Datenmaterial überschaubarer zu
machen.
Kein
datenreduzierendes Verfahren.
Aufgrund der Komplexität und des iterativen Charakters der Methode ist Computereinsatz unabdingbar.
Zur Kategorie der Explorativen Datenanalyse gehörend.
Das
Skalenniveau der
Regressionsbaum
sagt man, wenn die unabhängigen Variablen
Liegen unabhängige Variablen auf metrischer Skala vor, dann werden diese in Klassen eingeteilt, wobei die Festlegung der Klassengrenzen Bestandteil der Bildung eines "optimal verzweigenden" Baumes ist.
Das Wort "eines" in vorigem Satz impliziert, dass es nicht nur eine mögliche Verzweigungskonstellation des Baumes zu einem gegebenen Datenmaterial zu geben scheint. Eine Verzweigung sollte so sein, dass die beiden Zweige maximalen Unterschied bezüglich des betrachteten Merkmals aufweisen.
Methoden, die die Generation eines Entscheidungsbaumes automatisieren, sind z.B. CART und CHAID.
Je höher der Automatisierungsgrad, desto eindeutiger sind "optimale" Verzweigungskonstellationen.
Im binären Entscheidungsbaum wird eine Serie von Fragen gestellt, welche alle mit Ja oder Nein beantwortet werden können. Bei jedem Knoten wird ein Merkmal abgefragt und eine Entscheidung getroffen. Dies wird so lange fortgesetzt, bis alle Merkmale abgearbeitet sind und man sozusagen zwei "Blätter" des Baumes erreicht hat (für jeden Zweig 1 Blatt).
Entscheidungsbäume trennen die Daten in mehrere Gruppen, welche jeweils durch eine Regel mit mindestens einer Bedingung bestimmt werden.
Um eine Entscheidung (oder Klassifikation) abzulesen, geht man einfach den Baum entlang abwärts.
Ein Entscheidungsbaum wird oft auch deswegen Klassifikationsbaum genannt, wenn er nicht mehr primär zur Entscheidungsfindung, sondern zur visuellen Darstellung der vorgegebenen Klassen dient.
Entscheidungsbäume werden verwendet,
um sicherer Entscheidungen treffen zu können,
um die Stellen maximaler Unterschiede im gegebenen Datenmaterial herauszufinden
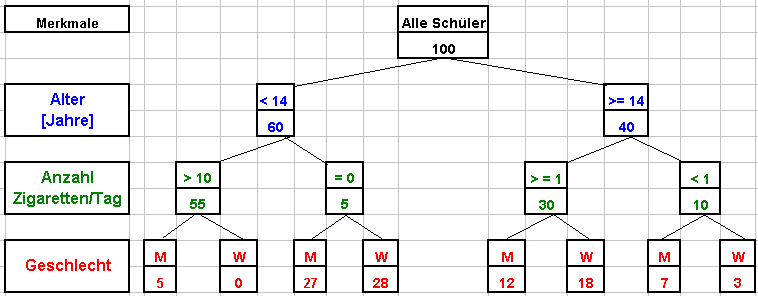
Beispielskizze
Die abhängige Variable soll das Geschlecht sein, die unabhängigen Variablen sollen Alter und Rauchverhalten sein.
Gesucht ist die maximal mögliche Unterscheidung zwischen den Geschlechtern am Ende des Baumes.
In diesem Beispiel mag der Rechenalgorithmus herausgefunden haben, dass es den grössten Informationsunterschied bringt, wenn man im ersten Klassifikationsschritt das Alter auswählt und die Altersgrenze bei 14 Jahren zieht.
Dies ist nämlich genau die Grenze, die bei dem als nächstes untersuchten Merkmal "Anzahl Zigaretten/Tag" den denkbar grössten Unterschied bringt. Von denjenigen Schülern, die unter 14 Jahre alt sind, gibt es eine deutliche Unterscheidung im Rauchverhalten: Es scheint hier eine ´Bande aus 5 Buben zu geben, die stark raucht. Der Rest unter 14 raucht überhaupt nicht.
Der Unterschied im anderen Zweig der 14- und Mehrjährigen bekommt man zunächst keinen derart grossen Unterschied, wohl aber im letzten Schritt: Die stärkeren Raucher sind eher Frauen, die schwächeren Raucher eher Männer.
Hätte man die Altersgrenze im ersten Klassifikationsschritt beispielsweise bei 15 oder 13 Jahren gezogen, dann wäre die zuvor geschilderte Information bei weitem nicht so deutlich aus dem Baum ersichtlich gewesen.
Abgesehen von dem Rechenalgorithmus kann auch der Benutzer die Klassifikationsreihenfolge sowie die Klassengrenzen festlegen.