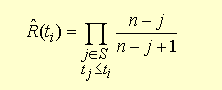
Methode zur Bestimmung der mittleren Lebensdauer unter statistisch widrigen Randbedingungen.
Diese Methode wird -unter diesem Namen- besonders in klinischen Forschung angewandt.
Charakteristika:
Zeitintervalle werden durch Ereignisse festgelegt und sind im Normalfall unterschiedlich lang
In jedem Zeitintervall können neue Testobjekte hinzukommen oder laufende Testobjekte herausfallen.
Die Kaplan Meier Methode wird bei Überlebenszeitanalysen angewandt, bei denen nicht alle Individuen der gesamten Testdauer ausgesetzt sind. Verfolgt man beispielsweise die Zuverlässigkeit von Motoren einer neuen PKW-Serie, dann protokolliert man, wieviele Fahrzeuge der neuen Serie nach welcher Zeit aufgrund Motorschaden ausgefallen sind und erhält somit die mittlere Lebensdauer der Motoren.
In der Praxis ergeben sich jedoch üblicherweise wesentliche Erschwerungen.
Es ist meisstens unmöglich, eine Studie solange zu betreiben, bis alle Individuen ausgefallen sind. (Nur dann wäre die maximal mögliche Aussagesicherheit erreicht) Man muss die Studie sozusagen „abbrechen“.
In der Praxis können Individuen auch aus anderen, eigentlich nicht interessierenden Gründen ausfallen. Im Beispiel der PKW Studie werden sicher einige Fahrzeuge einen Totalschaden aufgrund eines Unfalls erleiden. Diese Individuen fallen also nicht aufgrund eines Motorschadens aus, sondern ihre Beobachtungszeit wird durch ein eigentlich nicht interessierendes Ereignis beendet.
Oft steigen einige Individuen später in den Test mit ein. Im Beispiel der PKW Studie werden nicht alle verfolgten PKW’s am selben Tag zugelassen, sondern die Testpopulation steigt mit der Anzahl Käufer kontinuierlich an.
Oft ist es nicht möglich, die genauen Ausfallzeitpunkte zu erfassen. Im Beispiel der PKW Studie ist es schon aufwendig genug, bei den Fahrzeughaltern einmal jährlich die Information über den Zustand der Motoren einzuholen.
Die Kaplan Meier Methode berücksichtigt nur die Punkte 1.) bis 3.)
Das Wesentliche bei der Kaplan Meier Methode ist, dass man die Grenzen der Beobachtungsintervalle an diejenigen Zeitpunkte legt, an denen mindestens 1 interessierendes Ereignis (Ausfall) stattgefunden hat. Es ergeben sich demnach Intervalle unterschiedlicher Länge.
Bei den aus nicht interessierenden Gründen ausgefallenen Individuen wird angenommen, dass sie bis zum Ende desjenigen Intervalls überlebt hätten, in dem sie aus dem Test entfernt wurden.
Voraussetzungen der Kaplan Meier Methode:
Alle Individuen sind unabhängig und folgen der selben Verteilungsfunktion. Diese braucht nicht bekannt zu sein (also eine parameterfreie Methode
Zensorisierte Individuen (also diejenigen, die aus eigentlich nicht interessierenden Gründen ausfallen) sind zufällig verteilt.
Mit der Kaplan Meier Methode erhält man also eine diskrete treppenartige Verteilungsfunktion, für die mittels Regression oder Maximum Likelihood Estimation eine bestangepasste „wahre“ Verteilungsfunktion ermittelt werden kann.
Im
Folgenden ein Zahlenbeispiel.
20 Individuen werden werden bei t=0 in Betrieb genommen. Folgende Tabelle gibt die Zeitpunkte an, an denen Individuen ausgefallen sind oder ohne Ausfall ausser Betrieb gesetzt (zensorisiert) worden sind.
| Zeitpunkt | 10 | 32 | 50 | 56 | 98 | 100 | 122 | 125 | 150 | 181 |
| Anzahl ausgefallen | 1 | 1 | 1 | 1 | 1 | 1 | ||||
| Anzahl zensorisiert | 1 | 1 | 1 | 1 | ||||||
| Anzahl noch im Test | 19 | 18 | 17 | 16 | 15 | 14 | 13 | 12 | 11 | 10 |
Es ergeben sich folgende Kaplan Meier Schätzwerte:
R(10) = 19/20
R(32) = 19/20 x 18/19
R(56) = 19/20 x 18/19 x 16/17
R(98) = 19/20 x 18/19 x 16/17 x 15/16
R(122) = 19/20 x 18/19 x 16/17 x 15/16 x 13/14
R(181) = 19/20 x 18/19 x 16/17 x 15/16 x 13/14 x 10/11
Angenommen, es kommen während des Tests zu 2 Zeitpunkten neue Individuen hinzu. Diese Situation entspricht dann 3 Tests, die zu unterschiedlichen Zeitpunkten gestartet worden sind.
Die Ausfallzeitpunkte der später hinzugekommenen Individuen sind dann relativ zu zu ihren Startzeitpunkten zu sehen.
Beispiel:
Kommt z.B. nach 100 Stunden ein Individuum hinzu, und fällt dieses nach 70 Stunden (also zum Zeitpunkt 170h) aus, dann wäre obige Tabelle um Folgendes zu ergänzen:
- einen Ausfallzeitpunkt 70 mit einem Ausfall,
- die "anfängliche" Populationsgrösse wird zu n = 21 statt n =20. Alle vorkommenden Zahlen in den Kaplan Meier Schätzwerten müssten um 1 erhöht werden.
Man könnte diese 6 R-Werte nun konkret ausrechnen und im einfachsten Fall in ein Koordinatensystem einzeichnen und schliesslich per Augenmass eine Ausfallratenfunktion einzeichnen.
Im realen praktischen Fall wird eine Berechnungssoftware alles Weitere abnehmen.
Anmerkungen:
Der allgemeine Ausdruck für die Kaplan Meier Schätzwerte lautet:
ti sind die Ausfallzeitpunkte, n die anfängliche Popupulationsgrösse. Der Rest ist wohl etwas schwierig zu verstehen, aber die Logik ergibt sich klar aus dem obigen Beispiel.
Nachteilig ist, dass die bisherige Rechenweise pessimistisch (konservativ) ist. Am Einfachsten sieht man das, dass R =0 wird, wenn das letzte Individuum ausgefallen ist.
Realistischerweise müsste aber R sich asymptotisch dem Wert 0 nähern, wenn die Zeit gegen unendlich geht, und zwar unabhängig von der dahinter stehenden Verteilungsfunktion.
Deshalb modifiziert man die Kaplan-Meier Schätzer wie folgt:
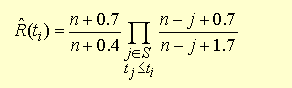
Der Bruch vor dem Produktzeichen ist ein Korrekturfaktor, der dafür sorgt, dass die ermittelten R-Werte besser in ein Wahrscheinlichkeitsnetz eingetragen werden können.
Er ist eine Näherung und kommt auf ähnliche Weise zustande wie die "Benards Median Ranks" bei der Weibullanalyse. Näheres hierzu befindet sich unter Weibullnetz.
Der tiefere Grund inklusive Herleitung, weshalb die auf einfache Weise weiter oben ermittelten R-Werte nicht mit den "wirklichen" R-Werten übereinstimmen, wird hier beschrieben: Beta-Binomiale-Vertrauensintervalle.