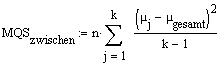
Mittlere Quadratesumme z
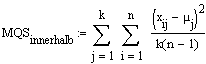
µj: Mittelwert der j-ten Stichprobe,
µgesamt: Gesamtmittelwert
k: Anzahl Stichproben
n: Anzahl Werte in jeder Stichprobe (Stichproben sind gleich gross)
Fisher
Pitman Test und Fishers exakter Test sind Randomisierungstests,
auch Resampling genannt. Der Fisher Pitman Test wird auf die
Mittelwerte zweier unabhängiger Stichproben, und der Fishers exakter
Test auf die Mittelwerte zweier abhängiger Stichproben
angewendet.
Zurück zum Glossar (Fisher Pitman)
Der Fisher Pitman Test ist ein Randomisierungstest für 2 unabhängige Stichproben.
Bei 2 abhängigen Stichproben siehe dagegen weiter unten Fisher's Randomisierungstest.
Prüft, ob die Mittelwerte zweier Stichproben gleich sind.
Wie
bei (fast) allen Randomisierungstest liegt der Wesenszug darin, alle
denkbaren Möglichkeiten durchzuspielen und die kumulierte
Beispielskizze:
1.)
Ausgangswerte
| Messwerte | Mittelwert | Anzahl Werte | |||||||
| Messreihe 1 | 18 | 24 | 25 | 22,67 | 3 | ||||
| Messreihe 2 | 21 | 29 | 29 | 30 | 31 | 31 | 31 | 28,86 | 7 |
2.)
Randomisierung
Man wirft alle 10 Werte der beiden Messreihen in einen Topf und zieht 3 beliebige Werte für Messreihe 1. Messreihe 2 ergibt sich dann aus den restlichen Werten.
Um aus 10 Werten 3 ohne Zurücklegen zu ziehen gibt es [10 über 3] Möglichkeiten.
Mit der Excelfunktion KOMBINATIONEN(10;3) berechnet man hierfür 120 Möglichkeiten.
Durch Ausprobieren, was in diesem beispiel wohl einfach, im Allgemeinen aber manuell eher unmöglich ist, ermittelt man, dass der Mittelwert von 22,67 für die erste Stichprobe lediglich von 2 weiteren Kombinationen noch unterschritten wird: (18,21,24) und (18,21,25).
Da
bei Gültigkeit der Nullhypothese ("Alle Werte der
beiden Stichproben sind zufällig") alle Kombinationen gleich
wahrscheinlich sind, beträgt die kumulierte
Das Signifikanzniveau liegt also bei 95%.
Für eine Exceldatei mit dem Fisher Pitman Test für 2 Stichproben mit zusammen bis zu 15 Werten siehe hier.
Da die Datei mehrere MB gross ist gibt es sie hier gezippt.
Bei grösseren Stichproben ist der t-Test vorzuziehen, weil der Rechenaufwand beim Fisher Pitman Test mit der Stichprobengrösse unverhältnismässig steigt.
Ausdehnung auf mehrere Stichproben.
Bedingungen:
Alle Stichproben gleich gross
Falls nicht, --> Erweiterter Mediantest. (Dabei wird wohl Information verschenkt; dafür kann man jedoch wenigstens ÜBERHAUPT testen)
Alle Populationen, aus denen die Stichproben gezogen worden sind, sind symmetrisch verteilt und formgleich
Falls nicht, dann gilt der Test immerhin noch auf Unterschiede in den Medianen.
Die folgende Vorgehensweise entspricht der einer ANOVA, weshalb man auch von einer Randomosierungs- Varianzanalyse spricht.
1.)
Ziehen von k Stichproben mit jeweils n Werten.
2.)
Berechnung der mittleren Quadratesummen und des F-Wertes (Siehe auch F-Test)
| Mittlere Quadratesumme z |
|
|
µj: Mittelwert der j-ten Stichprobe, µgesamt: Gesamtmittelwert k: Anzahl Stichproben n: Anzahl Werte in jeder Stichprobe (Stichproben sind gleich gross) |
|
Der F-Wert ist der Quotient
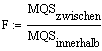
Dies ist der empirische F-Wert für die vorliegenden Daten.
3.)
Berechnung aller F-Werte für alle denkbaren Kombinationen.
Es gibt
insgesamt 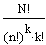 Möglichkeiten, N Werte auf k Stichproben der Grösse n zu verteilen.
Möglichkeiten, N Werte auf k Stichproben der Grösse n zu verteilen.
Sei Z
die Anzahl derjenigen Möglichkeiten davon, deren F-Wert grösser oder
gleich gross ist als der F-Wert der vorliegenden Daten, dann berechnet
sich das Signifikanzniveau zu 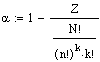 .
.
Dieser Test ist bereits für 3 sehr kleine Stichproben ohne spezielle Software kaum praktikabel.
Zurück zum Glossar (Fisher Pitman)
24.08.2005
Zurück zum Glossar (Fisher's Randomisierungstest)
Fisher's Randomisierungstest (exakter Test)
Randomisierungstest für 2 abhängige Stichproben.
Bei 2 unabhängigen Stichproben siehe Fisher Pitman Test.
Prüft, ob die Messwerte zweier Messreihen sich vor und nach der Messwiederholung unterscheiden.
Wie
bei (fast) allen Randomisierungstest liegt der Wesenszug darin, alle
denkbaren Möglichkeiten durchzuspielen und die kumulierte
Beispielskizze:
1.) und 2.)
Ausgangswerte und Berechnung der gerichteten Differenzen zwischen allen Wertepaaren.
| Messwerte | Anzahl Werte | ||||||||||
| Messreihe 1 | 17 | 22 | 22 | 15 | 24 | 22 | 21 | 21 | 17 | 21 | 10 |
| Messreihe 2 | 20 | 21 | 21 | 22 | 24 | 22 | 23 | 21 | 22 | 23 | |
| Gerichtete Differenz | -3 | +1 | +1 | -7 | 0 | 0 | -2 | 0 | -5 | -2 | |
2.)
Prüfgrösse ist die Summe der gerichteten Differenzen der vorliegenden Stichproben.
S= -17.
Nun
spielt man alle Vorzeichenkombinationen der gerichteten Differenzen
durch und berechnet die kumulierte
Man sieht in diesem Beispiel recht einfach, dass diese Kombinationen nur durch Verdrehen der Vorzeichen der gerichteten Differenzen +1, +1, -2 und -2 entstehen. Bei 6 dieser Möglichkeiten wird -17 erreicht oder unterschritten.
Nulldifferenzen sind wie normale Differenzen zu behandeln, was gleichbedeutend ist mit dem Weglassen der Nulldifferenzen.
Insgesamt ergeben sich 210 Möglichkeiten mit Berücksichtigung der Nulldifferenzen. Bei 6*23 Möglichkeiten (wieder mit Berücksichtigung der Nulldifferenzen, die 23 steht für die 3 Nullen) wird -17 erreicht oder unterschritten.
Da bei Gültigkeit der Nullhypothese ("Alle Differenzen der beiden Stichproben sind zufällig") alle Vorzeichenkombinationen gleich wahrscheinlich sind, beträgt die kumulierte Wahrscheinlichkeit für diese beiden und die vorliegende Kombination also [6*23]/[210] = 4,69%, was identisch ist mit [6]/[27] = 4,69%, ohne Berücksichtigung der Nulldifferenzen.
Das Signifikanzniveau liegt also bei 95,31%.
Für eine Exceldatei mit dem Fisher Radomisierungstest für 2 Stichproben mit je bis zu 15 Werten siehe hier.
Da die Datei mehrere MB gross ist. gibt es sie hier gezippt.
Bei grösseren Stichproben ist der t-Test (für abhängige Stichproben) vorzuziehen.
Anmerkung
Fisher's Randomisierungstest gewichtet die Vorzeichen der Differenzen nach ihrem Betrag.
Der Vorzeichen Rangtest hingegen gewichtet die Differenzen "nur" nach ihrem Rang in der geordneten Rangreihe.
Der Vorzeichentest dagegen gewichtet lediglich nach der Anzahl positiver und negativer Differenzen.
Zurück zum Glossar (Fisher's Randomisierungstest)
24.08.2005